この記事のポイント
- AI エージェントの危険性は prompt injection だけでなく、承認済み agent の権限肥大化にもあります。
- search、repo、ticket、cloud、browser を一つの agent に束ねるほど scope creep が起きやすくなります。
- 最小権限、短命 credential、approval flow、monthly review を組み合わせると drift を抑えやすくなります。
まず無料で確認する
無料でASM診断を開始
AIエージェント 権限で触れている論点は、自社ドメインを実際に診断すると優先順位が掴みやすくなります。まずは外部公開資産を無料で可視化してください。
AIエージェントの過剰権限とは何か
AI エージェントの過剰権限は、便利さのために接続先と権限を積み増した結果、scope と責任境界が膨らみ続けるところから始まります。
過剰権限の本質は『agent が何でもできる状態』ではなく『役割が曖昧なまま権限が増えること』です
AI エージェントの過剰権限とは、単に強い token を一つ持っていることだけを指しません。本質は、検索、要約、repo 参照、ticket 更新、browser 操作、cloud 実行、通知送信など、役割の異なる仕事を一つの agent に集め、そのたびに permission を継ぎ足していくことです。最初は read-only の helper だった agent が、いつの間にか write、execute、publish、approve までできるようになる。これが scope creep の典型です。
この問題が厄介なのは、権限追加が一つひとつは合理的に見えることです。「ticket も読めた方が便利」「repo も見せたい」「browser も動かしたい」「ついでに cloud も触れた方が運用が早い」と積み重なると、agent の目的より権限の方が先に広がります。すると誤作動、設定ミス、context 汚染、operator mistake のどれが起きても、影響範囲が広くなります。つまり危険なのは AI 自体より、権限の増え方に歯止めがないこと です。
既存の プロンプトインジェクションとは? が入力や文脈汚染を主役にするのに対して、本記事では「その agent がどこまで操作できるか」を主役にします。prompt injection がなくても、過剰権限の agent は人間の誤指示や設計ミスだけで十分危険です。だから AI security を考えるときは、入力境界と権限境界を別の層として設計する必要があります。
承認済みの agent でも安全とは限りません
シャドーAIのような未承認利用は分かりやすく危険ですが、承認済みの AI エージェントも、それだけで安全になるわけではありません。むしろ正式導入された agent ほど多くの内部資産と接続しやすく、権限 drift に気づきにくくなります。承認されたという事実が、かえって「この agent は触ってよい」という思い込みを広げ、permission の追加にブレーキがかからなくなることがあります。
既存の シャドーAIとは? が未承認利用と情報持ち出しを主役にしているのに対して、本記事は承認後の運用が中心です。つまり論点は「使ってよいか」ではなく、「承認済みならどの範囲まで許すのか」「誰が review するのか」「いつ取り消すのか」です。ここを設計しないと、正式導入後に一番大きなリスクが生まれます。
なぜ scope creep が起きやすいのか
agent は便利さの要求に押されて、複数業務の継ぎ足し先になりやすいからです
scope creep が起きやすい最大の理由は、AI エージェントが「汎用の助手」として期待されやすいからです。最初はナレッジ検索だけだったものが、次に ticket 要約、issue 下書き、repo 参照、CI ログ確認、デプロイ確認と増えていく。利用者から見ると一つの画面で完結する方が便利なので、agent へ権限を集める圧力が常に働きます。これが permission drift を生み、役割設計より convenience が勝つ状態 になります。
また、AI エージェントは API client や batch job より、会話の文脈でタスクを切り替えられるため、「今は調査だけ」「次は更新も」と境界が曖昧になりやすいです。人間は会話の延長で仕事を頼みますが、権限境界は会話ほど柔らかく扱えません。このギャップを埋めないまま agent を業務へ入れると、read-only のつもりで始めた agent が、実際には更新権限まで持っている 状態になります。
shared credential と長寿命 token が drift を固定化します
もう一つの原因は、agent 用 credential を簡単に済ませようとして shared token や長寿命 secret を使ってしまうことです。これをやると、agent ごとの責任分界が消え、どの task にどの権限を与えたのか追いづらくなります。既存の サービスアカウントのセキュリティとは? が示すように、shared identity は棚卸しと最小権限化を難しくします。AI agent でも同じで、shared token は便利でも、権限 drift を長期保存してしまう容器 になりがちです。
さらに shared credential は、一つの token で repo、ticket、browser automation、cloud operation をまたげる構成を生みやすくします。そうなると、どこか一つの integration が壊れても影響範囲が広がり、review でも「この権限は何のためか」が説明しにくくなります。だから scope creep 対策では、agent ごとに identity を分けることが非常に重要です。
agent ごとに用途と identity を分ける
一つの agent が repo、ticket、cloud、browser を横断すると、scope creep が起きやすくなります。
read / write / execute / publish を別権限として扱う
検索と更新、閲覧と実行を同じ token や approval で許すと、誤作動が重大操作へ伸びやすくなります。
長寿命 credential ではなく短命権限と承認フローを優先する
agent に常設の強権限を与えると、drift が起きても気づきにくくなります。
tool metadata と permission grant を定期レビューする
権限肥大化は一度の設計ミスより、継ぎ足しの運用で起きやすいからです。
MCP、repo、cloud、ticketing連携で何が危険になるのか
危険なのは tool が増えることより、権限と説明文が混線することです
MCP や tool 連携は非常に便利ですが、危険なのは tool の数そのものではありません。問題は、それぞれの tool が何を読めて、何を書けて、どの approval で実行されるかが曖昧なまま、一つの会話から呼ばれることです。OWASP MCP Top 10 が扱う「Privilege Escalation via Scope Creep」も、agent が便利さのために多機能化し、説明文や permission grant が積み上がることで境界が崩れる点を重視しています。
たとえば repo の read 権限だけのつもりで接続した tool が、branch 作成や PR 更新もできる。ticketing 連携が閲覧だけのつもりで、実は status 変更や comment 送信もできる。browser tool が確認用のつもりで、実際には download や form submit までできる。このように「説明上の役割」と「実際の権限」がずれると、operator は弱い権限のつもりで使い、system は強い権限で動きます。ここが過剰権限の一番危ない形です。
既存の シャドーAPIとは? や フロントエンドのAPIキー露出とは? が外部接点と secret の問題を扱うのに対し、本記事の焦点は「承認済みの tool 連携がどこまで操作できるか」です。つまり AI エージェントの過剰権限は API 漏えいではなく、統合済み接点の authorization drift として考えた方が実務に落とし込みやすくなります。
prompt injection との違いは、入力の問題ではなく authorization の問題であることです
prompt injection が文脈汚染や external content を通じて model の判断をずらす問題だとすると、AI エージェントの過剰権限は、そのずれた判断がどこまで実害に届くかを決める問題です。つまり prompt injection がなくても、operator が誤って広い task を頼めば危険ですし、逆に prompt injection が起きても権限が狭ければ被害を局所化できます。両者は近いですが、主役の層が違います。
そのため本記事では、「AI は危険だから使わない」という broad 論ではなく、承認済み agent を使う前提で、どこに approval と最小権限を置くか を整理します。NIST の secure AI system engineering でも、component ごとの boundary と dependency 管理が重要とされており、AI security をモデル内部だけの話にしないことが求められています。
最小権限、JIT昇格、承認フローをどう設計するか
read と write を分けるだけでも、事故の伸び方は大きく変わります
AI エージェントの権限設計で最初に効くのは、read-only と write / execute / publish を分けることです。調査、要約、下書きは read-only に寄せ、更新や送信が必要な操作は別の approval を通す。この段差だけでも、誤った判断が重大変更へ直結する確率を大きく下げられます。とくに repo、ticket、cloud、chat 通知は、一見小さな更新でも業務影響が大きいため、書込み系を別の層へ切り出す のが基本です。
実務では、AI agent に最初から管理者権限を与えるより、read-only の base role に必要な時だけ JIT 昇格を重ねる方が安全です。JIT は Just-In-Time 昇格の略で、常設の強権限ではなく、短時間・限定用途でのみ高い権限を付ける考え方です。これにより drift が起きても長期固定化しにくくなり、review でも「なぜその権限が必要だったか」を追いやすくなります。
per-agent identity と approval log が、説明可能性を支えます
agent ごとに identity を分けると、どの agent がどの resource に触れたかを説明しやすくなります。shared credential をやめ、用途別の identity と短命 token を使えば、repo 調査 agent、ticket triage agent、browser 検証 agent のように責任を切り分けられます。そうすると、同じ AI platform 上でも 何のために存在する権限か をレビューしやすくなります。
さらに approval log を残すと、どの task で誰が昇格を承認したか、どの tool が使われたか、どこで publish したかを後から追跡できます。これは監査のためだけでなく、誤作動時の切り分けにも効きます。AI エージェントの過剰権限対策は「止める仕組み」を入れるだけでなく、なぜその操作が許されたのかを説明できる状態 を保つことでもあります。
また、approval はボタン一つで済ませず、何を変更するのか、どの system へ書くのか、read-only ではなく write になるのかを分かる形で出すべきです。承認者が scope を理解できなければ、approval 自体が形だけになります。だから UI でも運用でも、「変更対象」「実行主体」「有効時間」「戻し方」を見えるようにしておく方が安全です。
agent 単位に目的・接続先・禁止操作を定義する
汎用 agent を一つだけ置くのではなく、調査、下書き、承認付き更新、実行支援など役割ごとに境界を分けます。
agent 台帳per-agent identity と短命 credential に寄せる
shared token ではなく agent ごとの identity、短命 token、用途別 scope へ寄せることで、誤作動時の影響範囲を縮めます。
権限分離表write / execute / publish に明示 approval を置く
read-only task と destructive task を同じ権限で扱わず、更新・送信・公開の直前で人の確認を挟みます。
approval flowtool metadata、接続先、権限 drift を月次で見直す
便利さのために追加した permission が積み上がりやすいため、grant の棚卸しを定例化します。
運用レビュー最新の official source と recent research から何を読むべきか
Anthropic の permission / IAM docs は『read-only default と policy override』を前提にしています
最新の official source で特に参考になるのは、Anthropic の Claude Code security と IAM です。Claude Code は read-only permissions を default にし、bash 実行や編集のたびに approval を要求する構造を明示しています。また IAM docs では、Teams / Enterprise、Console、Bedrock、Vertex、Foundry といった経路ごとに、認証と role の配り方が変わることも説明されています。ここから読めるのは、AI agent の安全性は model の賢さではなく、permission default と policy distribution の設計でかなり決まるということです。
さらに Anthropic の sandboxing 解説は、prompt injection が成功しても被害を局所化するために、bash や web 実行の隔離を重視しています。これはそのまま過剰権限の記事にも接続できます。つまり、入力汚染を完全に防げない前提で、権限を狭くし、実行面を分離し、強い操作だけを approval へ寄せる方が実務的だということです。AI エージェントの過剰権限を論じるなら、便利さより先に default permission と sandbox を見るべきです。
OWASP MCP Top 10 と Agent Skills 研究は、権限昇格を ecosystem 問題として扱っています
recent research でも、過剰権限は個別 agent の設定ミスだけではなく、skill / tool ecosystem 全体の問題として扱われ始めています。OWASP MCP Top 10 が「scope creep」を独立論点として置いているのは、MCP や tool 連携が増えるほど、説明文、permission grant、approval boundary がずれやすいからです。これは単なる prompt の問題ではなく、authorization が継ぎ足しで崩れる構造だと理解した方がよいです。
2026年の「Agent Skills in the Wild」も、skill marketplace にある vulnerability の中で、data exfiltration と privilege escalation が高頻度で見つかることを示しています。instruction-only より executable script を含む skill の方が危険度が高いという結果は、MCP と AI agent を現場へ入れるときに非常に示唆的です。つまり、便利な skill を増やすほど権限境界は崩れやすくなり、承認済み integration でも安心できないということです。AI エージェントの過剰権限は、個別ツールの設定だけでなく、どの ecosystem を許可するかまで含めて考える必要があります。
実務では、official source と research を読む順番も大切です。先に vendor docs で permission default と approval の考え方を押さえ、その後に OWASP や recent paper で ecosystem 側の崩れ方を見ると、自社の agent 設計でどこを hard gate にするべきかがかなり明確になります。過剰権限対策は abstract な啓発ではなく、接続先ごとの許可設計に落とし込んで初めて効きます。
AIエージェントの公開接点を整理するならASM診断 PRO
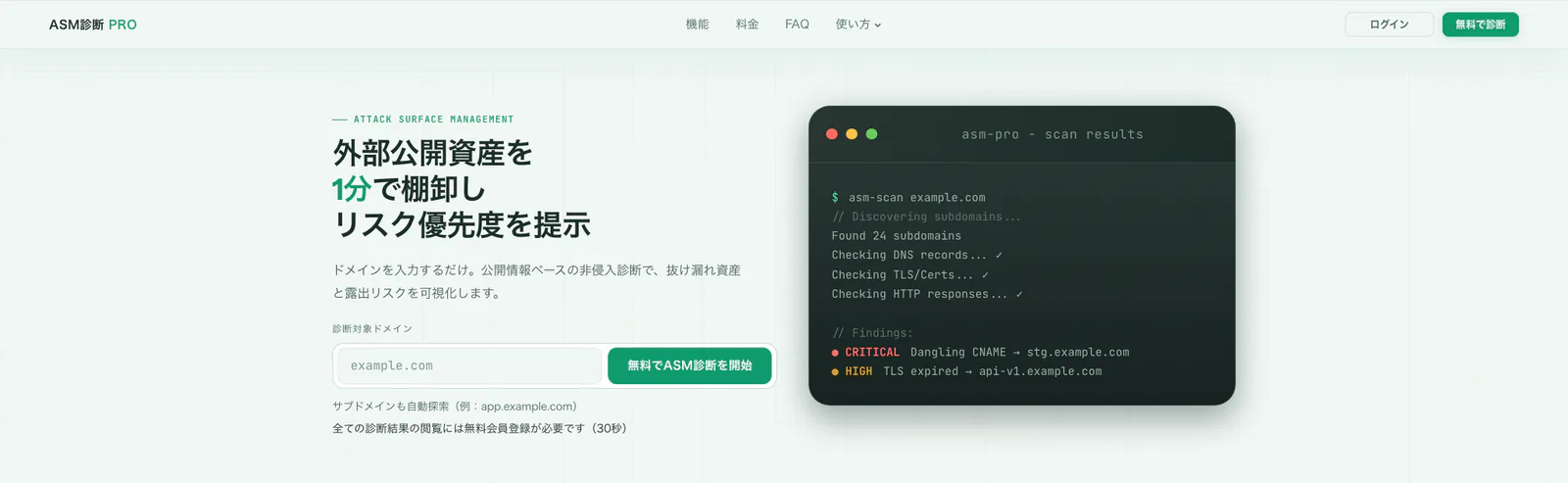
ASM診断 PRO は agent が参照・操作しうる公開 host、API、古い docs、staging を外から棚卸しし、権限肥大化と結びつく接点を整理する入口として使いやすい構成です。
ASM診断 PRO は MCP の approval engine でも、agent framework の権限制御製品でもありません。それでも価値があるのは、AI エージェントが最終的に触れる外部公開面を、外から見える接点として棚卸しできること です。repo、API、管理画面、staging、support docs、古い subdomain が乱立していると、agent ごとの権限分離をしても「そもそも何に触らせるべきか」が曖昧なままになります。
とくに AI agent の過剰権限は、権限の強さだけでなく、接続先の多さと説明の曖昧さから生まれます。どの host が現役か、どの API が公開されているか、古い docs や sample endpoint が残っていないかを把握できていないと、approval flow も per-agent identity も運用へ落とし込みにくくなります。ASM診断 PRO を使うと、外部公開面を起点に「agent に触らせる必要がある接点」「閉じるべき接点」「read-only で十分な接点」を整理しやすくなります。
既存の シャドーAPIとは?、サービスアカウントのセキュリティとは?、プロンプトインジェクションとは? と合わせて見ると、入力境界、機械ID、公開 API、agent 権限を一枚の運用へつなげられます。AI エージェントに権限を渡す前に、まずは 外から見える接点を棚卸しし、どこまで操作対象に含めるかを決めること から始めてください。
次のアクション
AIエージェントへ渡す前に、まず公開接点と操作対象を棚卸ししてください
無料で外部公開資産を診断し、agent が触れうる API、管理画面、docs、staging、subdomain を洗い出して、権限を与える対象と閉じる対象を整理する起点を作れます。
よくある質問(FAQ)
AI エージェントの過剰権限と prompt injection は同じですか
同じではありません。prompt injection は入力や文脈の汚染、過剰権限はその agent がどこまで操作できるかの問題です。両方が重なると被害が大きくなります。
agent を一つにまとめた方が管理しやすいのではないですか
一見楽ですが、役割と権限が混ざりやすく、scope creep を助長します。用途ごとに分けた方が review と最小権限化がしやすくなります。
read-only の agent なら approval は不要ですか
write や publish よりは軽くできますが、取得対象が広すぎると情報露出の問題が残ります。read-only でも対象範囲の設計は必要です。
shared token を短くローテーションすれば十分ですか
十分ではありません。ローテーションは重要ですが、identity が共有されたままだと責任分界が曖昧で、drift の原因が追いにくくなります。
最初に整えるべきものは何ですか
agent 台帳、用途別 identity、read/write の分離、approval flow の四つです。ここがないと後から便利機能を足すたびに権限が膨らみます。
まとめ

AI エージェントの過剰権限は、便利さのために接続先と権限を積み増した結果、責任境界が膨らみ続けることで生まれます。
AI エージェントの過剰権限は、危険な input が入ったときだけの問題ではありません。承認済みの agent でも、search、repo、ticket、browser、cloud を一つの helper に集め、shared credential と長寿命 token で動かしていると、scope creep が起きやすくなります。すると prompt injection、operator mistake、設定ミスのどれが起きても、被害の到達先が広くなります。したがって本質は「AI が賢すぎること」ではなく、役割が曖昧なまま権限を増やし続けること にあります。
実務で重要なのは、agent ごとに identity と用途を分け、read-only と write / execute / publish を分離し、必要なときだけ JIT 昇格で権限を渡すことです。これに approval flow と monthly review を組み合わせると、便利さを残しつつ drift をかなり抑えられます。AI エージェントの権限設計は、framework 比較より前に、誰が何のためにどこまで触れるかを説明できる状態を作ること から始まります。
さらに、権限設計は公開面の整理と切り離せません。agent が触れうる API、管理画面、docs、staging、sample endpoint が増えるほど、approval も最小権限も複雑になります。だから AI エージェントを安全に運用するには、入力境界、機械ID、外部公開面、approval を一つのガバナンスとして扱う必要があります。ここまで整理できると、AI agent を「便利だが危ない存在」ではなく、境界付きの業務基盤として扱いやすくなります。
次のアクション
読み終えたら、無料でASM診断を開始
外部公開資産の現状を無料で確認し、管理漏れや優先して見るべきリスクを洗い出してください。記事で読んだ内容を、そのまま自社の判断へつなげやすくなります。
参考にした一次ソース
重要論点の根拠として参照した一次ソースだけを掲載しています。
MCP を含む agent ecosystem 全体で注意すべき脅威の整理を確認するために参照しました。
scope creep を AI エージェント権限の中心論点として整理するために参照しました。
AI system engineering の観点から boundary と dependency をどう分けるべきかを整理するために参照しました。
prompt injection との違いと、MCP 周辺で権限設計をどう分けるかを補強するために参照しました。